

Nuevas vulnerabilidades de escalamiento en Linux (Ubuntu y Red Hat)
Vulnerabilidad LPE en snap-confine (en Ubuntu)
Investigadores de ciberseguridad han revelado detalles de una nueva vulnerabilidad de escalamiento de privilegios local (LPE) en snap-confine que un usuario sin privilegios puede activar para obtener acceso de administrador y el control total de un entorno objetivo.
Esta vulnerabilidad de alta gravedad, identificada como CVE-2026-8933 (CVSS: 7.8), afecta a las instalaciones predeterminadas de Ubuntu Desktop 24.04, 25.10 y 26.04. Esta revelación se produce en un contexto en el que se han publicado 442 vulnerabilidades de seguridad en Linux durante los últimos tres días.
"El problema se origina en un cambio de seguridad que introdujo inadvertidamente una condición de carrera durante la inicialización del entorno aislado", declaró Saeed Abbasi, jefe de la Unidad de Investigación de Amenazas (TRU) y director de producto en Qualys.
Snap-confine es un programa utilizado internamente por snapd para construir el entorno de ejecución de las aplicaciones snap. Snapd es el servicio en segundo plano o demonio que gestiona los paquetes snap en sistemas Linux. Snaps no es más que un formato de empaquetado de software ideado por Canonical que permite que una aplicación se ejecute de forma segura en un entorno aislado en la mayoría de las distribuciones de Linux.
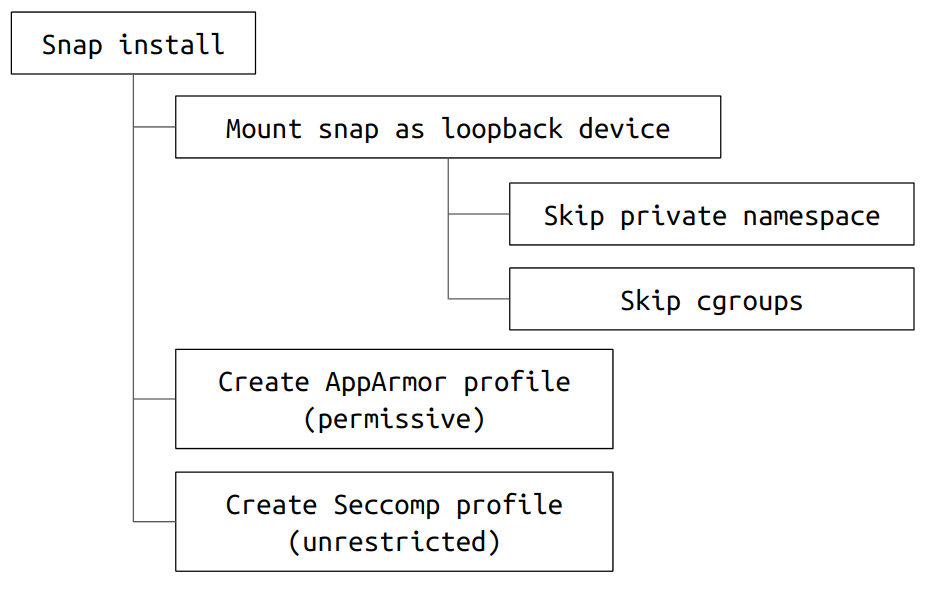
Aunque las versiones recientes de Ubuntu utilizan el modelo set-capabilities para aplicar el principio de mínimo privilegio (PoLP) y minimizar así la superficie de ataque, los cambios permiten que snap-confine se ejecute con el UID efectivo del usuario que lo llama, manteniendo al mismo tiempo capacidades cercanas a las de root.
"Durante la configuración del entorno aislado, el binario crea directorios y archivos temporales en /tmp que inicialmente pertenecen al usuario sin privilegios", explicó Qualys. "La propiedad se transfiere a root poco después, pero existe un breve lapso durante el cual quien llama conserva el control total".
El problema identificado por el proveedor de ciberseguridad es el resultado de dos condiciones de carrera concurrentes:
- Un atacante monta un sistema de archivos FUSE malicioso sobre el directorio temporal scratch inmediatamente después de su creación, eludiendo el aislamiento del espacio de nombres de montaje aplicado por snap-confine y manteniendo el directorio accesible fuera del entorno aislado.
- El atacante crea un enlace simbólico (también conocido como symlink) que apunta a un archivo de destino arbitrario, redirigiendo efectivamente las operaciones de archivo a ubicaciones sensibles del sistema.
Al manipular los permisos de archivo antes de que el sistema transfiera la propiedad, el atacante puede inyectar reglas maliciosas en los directorios del sistema y obtener ejecución de código como root, señaló Qualys.
"Cuando snap-confine intenta crear un archivo en el entorno aislado, la llamada a open() sigue al enlace simbólico y escribe en el destino. Una segunda condición de carrera permite al atacante ampliar los permisos de archivo a 0666 antes de que snap-confine llame a fchown() para transferir la propiedad a root".
Para eludir la protección de AppArmor, el exploit se dirige a la ruta /run/udev/**, que permite acceso de lectura y escritura. Al colocar un archivo .rules malicioso en /run/udev/rules.d/ y provocar un ciclo de montaje/desmontaje de FUSE, el atacante fuerza a systemd-udevd a ejecutar comandos arbitrarios como root.
Para contrarrestar el riesgo que supone la vulnerabilidad CVE-2026-8933, las organizaciones deben aplicar las últimas actualizaciones de snapd lo antes posible. "Un atacante aún necesita acceso de usuario o ejecución de código, pero la vulnerabilidad CVE-2026-8933 puede convertir ese acceso en control total del host", declaró Jason Soroko, investigador sénior de Sectigo. "Su presencia en las instalaciones predeterminadas de Ubuntu Desktop hace que las estaciones de trabajo de los empleados, los sistemas de los desarrolladores y los puntos finales administrativos formen parte del alcance de la respuesta".
Ubuntu 24.04 es relevante porque los sistemas actualizados pueden contener la variante afectada de snap-confine, lo que demuestra la importancia de que los administradores verifiquen la versión de snapd instalada en lugar de basarse en la antigüedad de la versión o el estado de los parches anteriores. Con las correcciones disponibles, la implementación y confirmación rápidas deben ser prioritarias.
Esta no es la primera vez que se descubren fallos de seguridad en el componente snap-confine. En febrero de 2022, Qualys detalló otro fallo de escalada de privilegios local, denominado Oh Snap! More Lemmings (CVE-2021-44731), que podía explotarse para obtener privilegios de root aprovechando una condición de carrera en la función setup_private_mount() de snap-confine.
Vulnerabilidad en RefluXFS (en Red Hat)
RefluXFS, una nueva vulnerabilidad del kernel de Linux revelada el 22 de julio y registrada como CVE-2026-64600, permite a un usuario local sin privilegios sobrescribir archivos propiedad del usuario root en un sistema de archivos XFS y obtener acceso root persistente.
Qualys afirmó que las instalaciones predeterminadas de Red Hat Enterprise Linux y sus derivados, Fedora Server y Amazon Linux cumplen las condiciones para su explotación.
La compañía demostró la competencia con los binarios /etc/passwd y setuid-root. La sobrescritura se produce en la capa de bloques. Sobrevive a un reinicio y deja intactos la propiedad, los permisos, las marcas de tiempo y el bit setuid del objetivo, por lo que un binario setuid-root modificado sigue ejecutándose como root.
La solución se integró el 16 de julio y los proveedores de Linux han comenzado a distribuir kernels retroportados. El parche rastrea el error hasta Linux 4.11 en 2017 en una correcciónmarcada como # 4.11.
¿Quiénes están expuestos?
La explotación requiere tres condiciones:
- El sistema ejecuta Linux 4.11 o posterior sin la corrección RefluXFS.
- El sistema de archivos XFS se creó con reflink=1.
- El objetivo legible y un directorio escribible por el atacante se encuentran en el mismo sistema de archivos XFS.
Qualys indicó que se debe parchear primero los sistemas expuestos y multiusuario, lo que significa cualquier host XFS con reflink habilitado donde se pueda ejecutar código no confiable localmente, ya sea a través de una shell, un trabajo de CI o un servicio comprometido.
El aviso enumera las instalaciones predeterminadas que pueden cumplir estas condiciones: Red Hat Enterprise Linux, CentOS Stream, Oracle Linux, Rocky Linux, AlmaLinux y CloudLinux 8, 9 y 10, Fedora Server 31 y versiones posteriores, Amazon Linux 2023 e imágenes de Amazon Linux 2 a partir de diciembre de 2022. Los sistemas de archivos de RHEL 7 no se ven afectados, ya que son anteriores a la compatibilidad con XFS reflink.
Debian, Ubuntu, SLES y openSUSE generalmente no utilizan XFS como sistema de archivos raíz de forma predeterminada. Solo se exponen si un administrador seleccionó XFS con reflink habilitado durante la instalación.
Verifique el sistema de archivos raíz:
xfs_info / | grep reflink=
reflink=1 significa que se cumple la segunda condición. Realice la misma
verificación en cualquier otro volumen XFS montado donde un archivo protegido
y un directorio con permisos de escritura para atacantes compartan el sistema
de archivos.
Qualys no publicó ningún código de explotación independiente. El sistema de seguimiento de Red Hat registró una prueba de concepto pública el 22 de julio, remitiendo al aviso publicado en la lista de correo oss-security, donde se detallan la carrera y los pasos para la explotación. Al momento de redactar este informe, ninguno de los proveedores que monitoreaban la vulnerabilidad había reportado su explotación en la práctica.
Red Hat ha emitido avisos de kernel de categoría Importante para las versiones afectadas de RHEL 8, 9 y 10. Las erratas comenzaron a aparecer el 14 de julio, ocho días antes de la divulgación coordinada: RHSA-2026:39179 y RHSA-2026:39180 para RHEL 8 y RHSA-2026:39494 para RHEL 10, y las versiones de soporte extendido y SAP se actualizaron hasta el 17 de julio. La instalación del paquete no reemplaza el kernel que ya se está ejecutando en memoria. Aplique la actualización del proveedor, reinicie el sistema y verifique que se esté ejecutando el kernel corregido.
Fuente: THN











