

#Cloudbleed: algunas enseñanzas de lo que sucedió con Cloudflare
 Cloudflare es una empresa que brinda servicios anti-DDoS, rendimiento web, CDN, WAF, ofuscamiento de correos y muchas otras ventajas, incluso gratuitamente. Estos, entre otros, son los motivos por los cuales utilizo Cloudflare desde hace 5 años en Segu-Info, y el evento reciente "de filtración de datos" me permite decir que no me he equivocado en mí elección. ¿Por qué? Sigue leyendo.
Cloudflare es una empresa que brinda servicios anti-DDoS, rendimiento web, CDN, WAF, ofuscamiento de correos y muchas otras ventajas, incluso gratuitamente. Estos, entre otros, son los motivos por los cuales utilizo Cloudflare desde hace 5 años en Segu-Info, y el evento reciente "de filtración de datos" me permite decir que no me he equivocado en mí elección. ¿Por qué? Sigue leyendo.Cloudflare ha dejado al descubierto una cantidad desconocida de datos, incluyendo contraseñas de usuarios, información, mensajes privados, APIs, cookies, etc.
Google mantiene el equipo de seguridad Project Zero que se dedica a analizar aplicaciones y programas en busca de vulnerabilidades. Hace una semana, el investigador de Project Zero, Tavis Ormandy alertó a Cloudflare de un problema que habría afectado a los datos de empresas como Uber, OKCupid, Fitbit, 1Password, entre muchas otras. Concretamente, se refiere a datos sobre las sesiones que estas compañías almacenan en sus servidores y se utilizan para validar a los usuarios ante estas aplicaciones.
Qué sucedió
Cloudflare ofrece, entre otros, un servicio CDN para la distribución de contenidos en una extensa red en todo el mundo. De un modo simple, redistribuyen los archivos de millones de sitios web (sus clientes) desde diferentes puntos geográficos y servidores para aliviar la carga sobre los servidores del portal web en cuestión, y para acelerar la descarga de sus archivos por parte de los usuarios.El "problema" es que en esta labor de intermediario, Cloudflare debe agregar código propio, utilizado para la detección de ataques, hotlinking, y otras medidas de seguridad. Esta tarea requiere parsear el código HTML del cliente y este parser tenía un bug, que provocó la filtración de datos de alrededor de 3.400 sitios webs.
El bug descubierto el 17 de febrero afectó a los proxies reversos de Cloudflare y causó que sus servidores de borde brindaran los datos sensibles, debido a que el error permitía retornar un buffer de memoria que contenía datos privados que no necesariamente correspondían al usuario correcto.
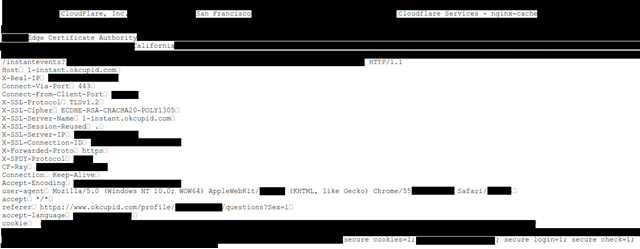
Básicamente el parser no procesaba adecuadamente ciertos tags HTML mal formados y finalmente mostraba cadenas que podían pertenecer a otras páginas o sitios web de terceros. Por ejemplo en la siguiente página se muestra una cabecera HTTP que pertenece a otro sitio web.
En su anuncio, Cloudflare menciona que el mayor impacto fue desde el 13 al 18 de febrero (fecha en que Ormandy también detectó el fallo) y habrían sido afectados alrededor de 3.300.000 de peticiones web (un 0.00003% de los requerimientos desde los CDN). Se trata de solicitudes a páginas (clientes de ClouFlare) con etiquetas mal formadas y que resultaron en la fuga datos.
Este tráfico es algo que se puede medir de manera factible, ya que pueden mirar el porcentaje de tráfico que están sirviendo. Sin embargo, lo que es dificil (y poco probable) es poder medir cuántos sitios tenían tráfico que realmente filtraba datos sensibles. Esta semana se publicó una lista no oficial de 4.288.852 sitios potencialmente vulnerables. Luego se publicó otra lista actualizada y no oficial de 5.319.353 dominios, entre los que figuraban los míos.

De acuerdo con el blog de Cloudflare, el problema se derivó de la decisión de la compañía de usar un nuevo analizador (parser) HTML llamado cf-html. Este parser es una aplicación basada en Ragel y compilada en C, que escanea el código HTML del cliente para extraer información relevante y poder modificarla con el código propio de Cloudflare.
Desde la empresa aseguran que su sistema de cifrado de extremo a extremo ha impedido que el problema sea mayor, pero lo cierto es que motores de búsqueda como Bing, Google o Yahoo! han guardado esta información en una copia caché de los portales web afectados.
En el comunicado explican que tan pronto como detectaron el problema, detuvieron los servicios que estaban permitiendo el acceso a información confidencial y se corrigió el parser. Desde Cloudflare ya se han puesto en contacto con los motores de búsqueda para eliminar la información filtrada, y se ha llevado a cabo la limpieza correspondiente en la mayoría de ellos.
Algunas enseñanzas
Es importante señalar que si bien el error podría (potencial) presentarse en cualquier sitio web servido desde los CDN de Cloudflare, sólo un pequeño porcentaje de sitios fue afectado y solo aquellos que manejaban información sensible -como usuario/contraseña, cookies, token, APIs, etc.- fueron los más perjudicados, debido a la criticidad de esa información que generalmente es transmitida a través de un canal HTTPS.Por su parte, los sitios HTTP afectados (como alguno de los míos) Segu-Info, Segu-Kids, Antiphishing y ODILA que también están en Cloudflare, pero no manipulan información sensible, no podrían haber sido víctimas de ningún ataque y ninguna fuga de información, simplemente porque la información nunca estuvo ahí.
Más allá de la gravedad del bug y del problema generado creo que es importante destacar estos puntos:
- La sinceridad del servicio de Cloudflare, informando del error y del procedimiento de seguimiento del incidente. Como digo al principio, creo que este procedimiento debe ser tomado como ejemplo por muchas empresas: el incidente nunca se niega, siempre se debe informar al cliente. Decirlo es fácil pero ni Google lo cumplió en su misterioso bloqueo de GMail, que nadie sabe porqué sucedió. ¿Habrá estado relacionado con la colisión en SHA1 y no quisieron reconocerlo?
- La "vulnerabilidad" a la que estamos expuestos todos aquellos que confiamos en la nube. Por ejemplo, el servicio 1Password (que almacena millones de contraseñas de millones de usuarios) no tenía una vulnerabilidad, pero su CDN era servido por Cloudflare, afectando a su vez a millones de usuarios.
- El tratamiento de incidentes debe contemplar la cadena de servicios, no solo un servicio. Por ejemplo ¿basta confiar y analizar una vez al año a mi proveedor de hosting o también debo analizar los cientos de servicios de terceros que dependen de ese primer servicio web? ¿Alguna vez analizaste cuántos servicios están involucrados en la página principal de tu sitio web? Aquí te muestro el mapa de Segu-Info para que te hagas una idea.
- Se debe conocer con quién se comparte información en un sitio web. Por ejemplo: 1Password compartía las APIs y sesiones con Cloudflare; los usuarios solo confían en 1Password (y ni conocen Cloudflare); pero, sin saberlo y por transitividad confían en Cloudflare. ¿Es correcto que esto sea así? ¿El negocio debería admitirlo? ¿El usuario no debería tener derecho a saber?
- Se debe ser consciente que el modelo de cloud computing centraliza la información, brindando un control (casi) completo al proveedor, y exponiendo a sus clientes y usuarios a riesgos que desconocen y son difíciles de percibir. De la misma manera, la anonimización del usuario se torna imposible, porque si el proveedor controla el contenido (HTML, JS, cookies, APIs, etc.) entonces es capaz de controla la interacción con el usuario y hace posible su identificación.
- Este evento fue "tapa de diario" durante 3 días. Realmente considero que fue un hype que llegó a ser Trend Topic, generado por el desconocimiento. El problema fue grave, pero eso no significa que fuera el fin de la nube tal y como la conocemos. Al contrario, debe enseñarnos algo de lo que menciono anteriormente. Solo para resumirlo, es más probable ganarse el Lotto que ser afectado por el bug.
- Por último, ¿ya cambiaste tus contraseñas de los servicios afectados, eliminaste las cookies y regeneraste las APIs?
Actualización 01/03/2017: la empresa comunicó que eliminó cerca de 80.000 páginas de unos 150 clientes que aparecían guardados en caché en los motores de búsqueda. En la actualidad no existe riesgo alguno para los dueños y usuarios de estas páginas. Todo parece indicar que nadie se percató del error además de Tavis Ormandy, no existiendo ningún registro de violación de seguridad.
Lic. Cristian Borghello, CISSP, CCSK
Director de Segu-Info


Hay un importante problema con las empresas globales de CDN y cloud-computing en general (Amazon AWS, etc.) y es que centralizan enormemente Internet. Si uno controla en cierta medida estas empresas, controla de hecho Internet. Se sabe que Amazon tiene lazos muy estrechos con la CIA (recibió hace poco un contrato de u$600M de la misma), es de suponer que CloudFlare & co también los tienen (sobre todo cuando te ofrecen servicios "gratuitos").
ResponderBorrarEntonces, al delegarles la entrega de algunos de los archivos (js, imágenes, etc.) o de todo el sitio en su totalidad (cuando las CDNs se utilizan en modo reverse proxy o http accelerators) exponemos a nuestros visitantes a diferentes riesgos, principalmente al rastreo y simplificación de ataques.
El rastreo se realiza al descargar el contenido desde los servidores de las CDNs y al tener que habilitar JS en la mayoría de los casos (esto hace la identificación prácticamente absoluta). El hecho de que las mismas CDNs se utilizan en una enorme cantidad de sitios web hace prácticamente imposible el anonimato y la privacidad (se puede saber el historial de la mayoría de las páginas visitadas y las interacciones con las mismas).
Los ataques se simplifican por el mismo motivo: al descargar el contenido desde un servidor controlado y al tener que habilitar JS, sólo hace falta un zero-day para tu navegador y un privilege escalation para que tu compu este bajo el control de las agencias (y con la identificación esto puede ser realizado de manera dirigida).
Problemas menos significativos son los bugs no intencionales como este que afectan a millones de sitios y la exposición de Internet en general a los ataques enfocados (sólo hace falta tirar abajo con un DDoS un par de empresas como estas para "apagar" Internet (como fue el caso Dyn)).